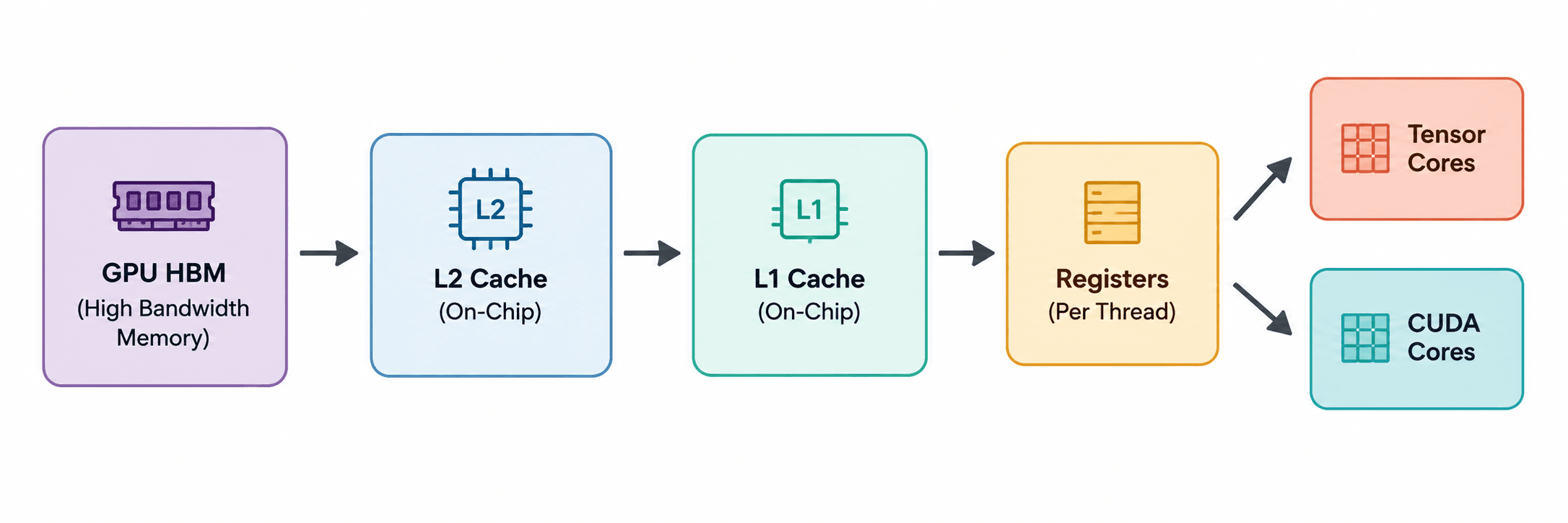
You'll often hear people say that the decoding phase of LLM inference is memory-bound.
It's one of those phrases that gets repeated so often that many people simply accept it without understanding why. Rather than memorising the term, let's walk through a simple example and see where it comes from.
We'll use a single NVIDIA H100 GPU and a 35-billion parameter model to keep the maths simple.
Our Example
Suppose we're serving a 35B dense model using FP16 (16-bit precision) on a single H100 SXM GPU with 80 GB of HBM.
Each FP16 parameter occupies 2 bytes, so the model weights alone require:
35 billion × 2 bytes = 70 GB
That leaves roughly 10 GB of HBM for everything else, including the KV cache, activations and other runtime memory.
What Happens During Decoding?
During decoding, the model generates one token at a time.
To produce each new token, almost every weight in the model needs to participate in the forward pass. Since we're only processing a single token, there is very little opportunity to reuse those weights while they're on-chip.
Instead, the GPU repeatedly streams the model weights from HBM into the Streaming Multiprocessors (SMs), where they're consumed by the Tensor Cores.
This immediately raises a question.
How long does it take just to read those weights from memory?
Reading the Weights
The H100 SXM provides approximately 3.35 TB/s of HBM bandwidth.
Ignoring every other overhead for a moment, the time required to read the model weights is simply:
Time = Data Size ÷ Memory Bandwidth
Substituting our numbers gives:
Time = 70 GB ÷ 3.35 TB/s
≈ 0.0209 seconds
≈ 20.9 milliseconds
Just moving the weights from HBM takes roughly 20 milliseconds.
That also gives us an approximate upper bound on throughput.
Tokens per second
≈ 1000 ms ÷ 20 ms
≈ 48 tokens/second
This is only a back-of-the-envelope estimate, but it's close enough to help us understand where the bottleneck comes from.
Now Let's Look at the Compute
Reading the weights is only half of the story.
We also need to know how long the GPU actually spends performing the calculations.
A common approximation is that a forward pass requires roughly 2 floating-point operations (FLOPs) per parameter per generated token.
Why two?
Each parameter is typically involved in:
- one multiplication
- one addition
which gives:
1 Multiply + 1 Add = 2 FLOPs
For our 35-billion parameter model, the total compute becomes:
35B parameters × 2 FLOPs
= 70 billion FLOPs
= 70 GFLOPs
Note: This is a simplified estimate that focuses on the dense matrix multiplications, which dominate the computation in large transformer models. It ignores additional operations such as attention, layer normalization and activation functions.
How Long Does the Computation Take?
An H100 Tensor Core GPU can sustain approximately 990 TFLOPS of FP16 Tensor Core performance (without structured sparsity).
The compute time is therefore:
Time = FLOPs ÷ Compute Throughput
= 70 GFLOPs ÷ 990 TFLOPS
≈ 0.0000707 seconds
≈ 0.07 milliseconds
Think about that for a moment.
The GPU only needs 0.07 milliseconds to perform all the matrix multiplications required to generate the next token.
Comparing the Two
Let's put both numbers side by side.
| Operation | Time |
|---|---|
| Read 70 GB of weights from HBM | ~20 ms |
| Perform all matrix multiplications | ~0.07 ms |
The difference is huge.
The GPU spends approximately 20 milliseconds waiting for the weights to arrive, but only 0.07 milliseconds actually performing the calculations.
Looking at it another way:
0.07 ms ÷ 20 ms
≈ 0.0035
≈ 0.35%
Only about 0.35% of the total execution time is spent performing arithmetic.
The remaining 99.65% is dominated by moving data from memory.
This is exactly what we mean when we say decoding is memory-bound.
The GPU has far more compute capability than this workload requires. The limiting factor isn't how fast the Tensor Cores can perform matrix multiplications, it's how quickly the model weights can be delivered from HBM.
Why Isn't the Prefill Phase Memory-Bound?
At this point you might be wondering:
If decoding is memory-bound, why isn't the prefill phase memory-bound too?
The answer is weight reuse.
During prefill, the model processes many input tokens at the same time.
When a layer's weights are loaded from HBM, those same weights are reused across every token in the sequence before the GPU moves on to the next layer.
That means much more computation is performed for every byte read from memory.
During decoding, things are very different.
Only one token is processed at a time.
The weights are loaded, used once to produce the next token, and then the GPU moves on. There is very little opportunity to reuse those weights before they need to be read again.
As a result, far less computation is performed for each byte transferred from memory, making memory bandwidth the limiting resource.
Key Takeaway
Decoding isn't slow because modern GPUs lack compute power.
An H100 can perform the required matrix multiplications in well under a millisecond.
The real bottleneck is getting tens of gigabytes of model weights from HBM to the Tensor Cores for every generated token.
Once you understand this, many LLM inference optimisation techniques start to make much more sense.
Quantisation reduces the amount of data that needs to be transferred. Continuous batching improves hardware utilisation. FlashAttention reduces unnecessary memory traffic. Faster memory systems increase bandwidth.
Although these techniques work in different ways, they all aim to solve the same underlying problem: reducing the amount of time the GPU spends waiting for data.